Architecture¶
High-level Architecture¶
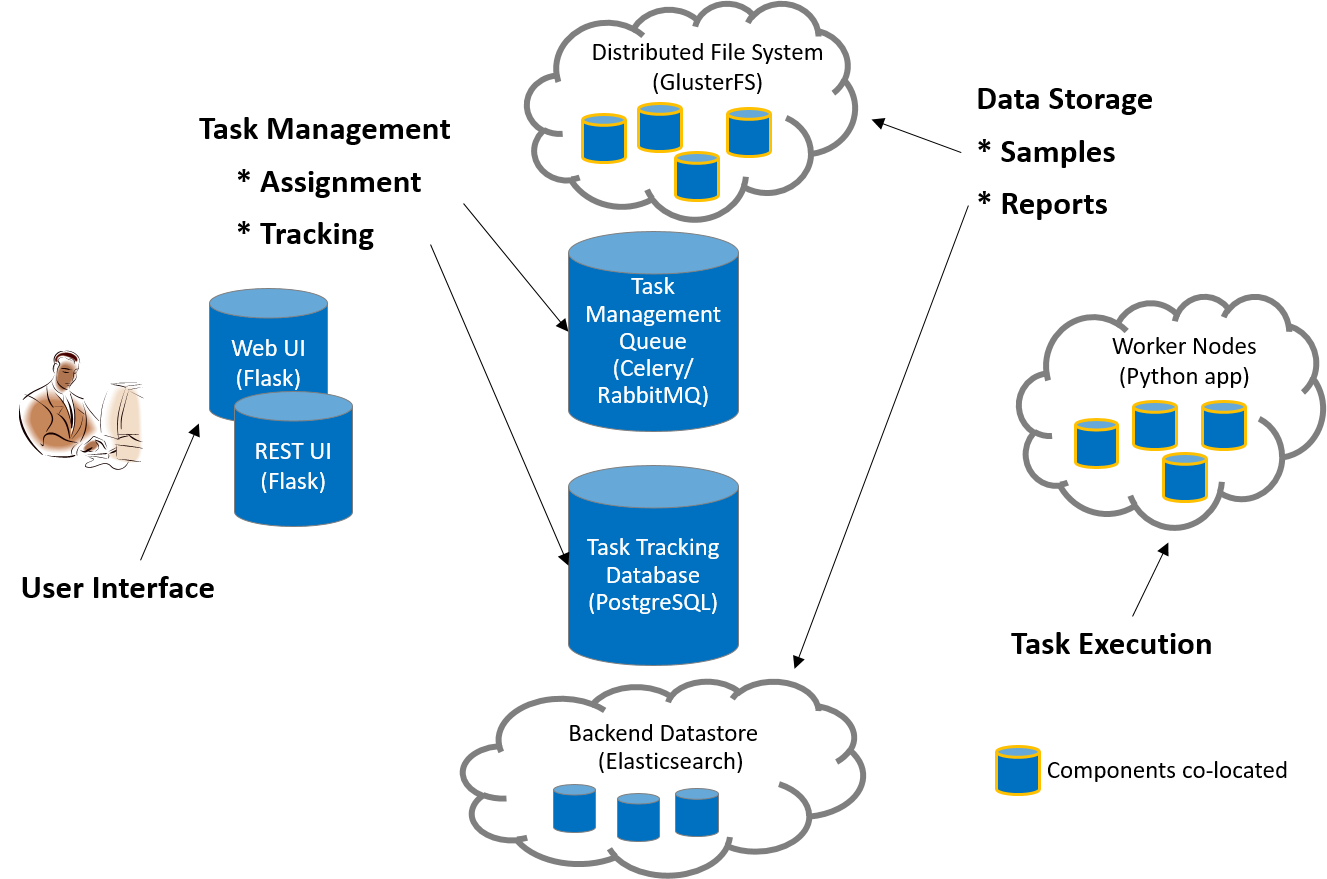
There are seven primary components of the MultiScanner architecture, as described below and illustrated in the associated diagram.
MultiScanner Architecture
Web Frontend
The web application runs on Flask, uses Bootstrap and jQuery, and is served via Apache. It is essentially an aesthetic wrapper around the REST API. All data and services provided are also available by querying the REST API.
REST API
The REST API is also powered by Flask and served via Apache. It has an underlying PostgreSQL database to facilitate task tracking. Additionally, it acts as a gateway to the backend Elasticsearch document store. Searches entered into the web UI will be routed through the REST API and passed to the Elasticsearch cluster. This abstracts the complexity of querying Elasticsearch and gives the user a simple web interface to work with.
Task Queue
We use Celery as our distributed task queue.
Task Tracking
PostgreSQL is our task management database. It is here that we keep track of scan times, samples, and the status of tasks (pending, complete, failed).
Distributed File System
GlusterFS is our distributed file system. Each component that needs access to the raw samples mounts the share via FUSE. We selected GlusterFS because it is more performant in our use case – storing a large number of small samples – than a technology like HDFS would be.
Worker Nodes
The worker nodes are Celery clients running the MultiScanner Python application. Additionally, we implemented some batching within Celery to improve the performance of our worker nodes (which operate better at scale).
A worker node will wait until there are 100 samples in its queue or 60 seconds have passed (whichever happens first) before kicking off its scan (these values are configurable). All worker nodes have the GlusterFS mounted, which gives access to the samples for scanning. In our setup, we co-locate the worker nodes with the GlusterFS nodes in order to reduce the network load of workers pulling samples from GlusterFS.
Report Storage
We use Elasticsearch to store the results of our file scans. This is where the true power of this system lies. Elasticsearch allows for performant, full text searching across all our reports and modules. This allows fast access to interesting details from your malware analysis tools, pivoting between samples, and powerful analytics on report output.
Complete Workflow¶
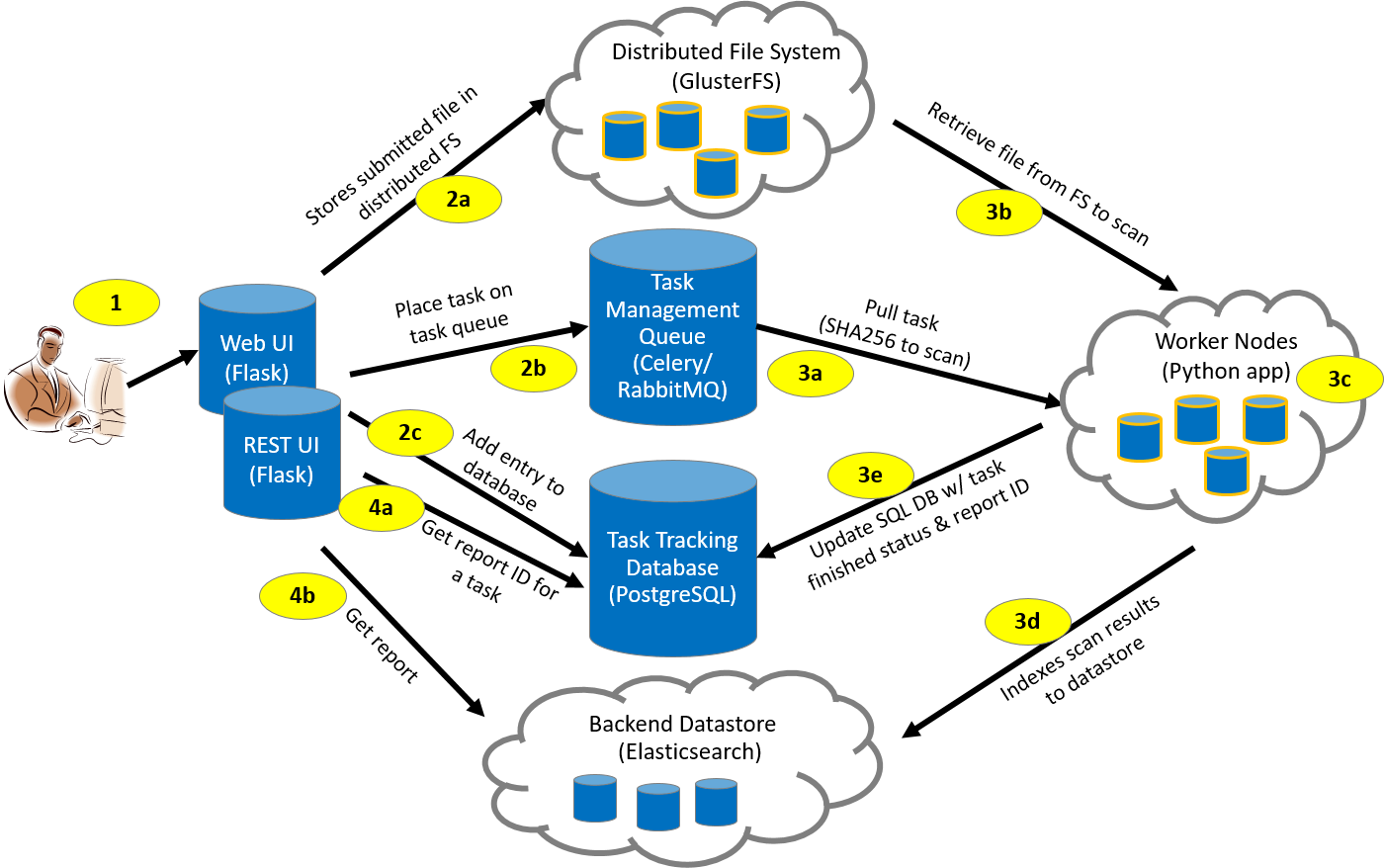
Each step of the MultiScanner workflow is described below the diagram.
MultiScanner Workflow
- The user submits a sample file through the Web UI (or REST API)
- The Web UI (or REST API):
- Stores the file in the distributed file system (GlusterFS)
- Places the task on the task queue (Celery)
- Adds an entry to the task management database (PostgreSQL)
- A worker node:
- Pulls the task from the Celery task queue
- Retrieves the corresponding sample file from the GlusterFS via its SHA256 value
- Analyzes the file
- Generates a JSON blob and indexes it into Elasticsearch
- Updates the task management database with the task status (“complete”)
- The Web UI (or REST API):
- Gets report ID associated with the Task ID
- Pulls analysis report from the Elasticsearch datastore
Analysis¶
Analysis tools are integrated into MultiScanner via modules running in the MultiScanner framework. Tools can be custom built Python scripts, web APIs, or software applications running on different machines. Catagories of existing modules include AV scanning, sandbox detonation, metadata extraction, and signature scanning. Modules can be enabled/disabled via a configuration file. Details are provided in the Analysis Modules section.
Analytics¶
Enabling analytics and advanced queries is the primary advantage of running several tools against a sample, extracting as much information as possible, and storing the output in a common datastore. For example, the following types of analytics and queries are possible:
- cluster samples
- outlier samples
- samples for deep-dive analysis
- gaps in current toolset
- machine learning analytics on tool outputs
Reporting¶
Analysis data captured or generated by MultiScanner is accessible in three ways:
- MultiScanner Web User Interface – Content in the Elasticsearch database is viewable through the Web UI. See Web UI section for details.
- MultiScanner Reports – MultiScanner reports reflect the content of the MultiScanner database and are provided in raw JSON and PDF formats. These reports capture all content associated with a sample.
- STIX-based reports will soon be available in multiple formats: JSON, PDF, HTML, and text.